

Windfall is on a mission to determine the net worth of every person on the planet. It is a massive data challenge, and our work enables us to stitch together thousands of data attributes and develop models around net worth. Given our unique vantage point, many of our customers have asked us to assist them in determining their ideal customer or donor profile.
With 500+ customers across the country, you can imagine that there are many challenges with scale. Imagine you are a new data scientist at Windfall, and you’ve created a model for a customer:
- How do you collaborate with other data scientists on the team to get feedback?
- What does an engineer need to know to productionize it?
- How do you deploy it for customers on an ongoing basis?
- What documentation or software artifacts need to be persisted for later use?
In this post, we’ll review some of the challenges that Windfall has faced with deploying predictive models at scale, our solution called Model Manager, and how we’ve significantly reduced the time to build scalable machine learning models, while rapidly increasing the numbers of models we can support.
Framing the Challenge: Deploy Models at Scale
Productizing and deploying data science models can be challenging. Part of the problem is that generally, no sole individual can own the entire process. Data scientists are the statistician specialists who actually build the models, while engineers focus on building scalable production-level architectures. On top of this, data science and engineering technology choices have some significant differences. For instance, exploratory data analysis (“EDA”) and modeling generally is executed in dynamically-typed scripting languages such as R and Python, while REST services and hardy production systems are oftentimes built using statically-typed JVM languages or Go.
At Windfall, we regularly create bespoke predictive models for many of our clients and have quickly encountered this problem. For instance, we offer nonprofit propensity models that score the likelihood of a constituent to give to a particular organization based on attributes/features such as net worth, past giving, or other demographic attributes. Every model is organizational-specific for each of our customers, and oftentimes we’re creating even more than one model per customer. This means we do NOT duplicate models with the same use case for multiple customers; each is specific for that customer. Needless to say, our collection of custom models has grown quite rapidly and managing all of these would quickly become unwieldy, especially considering Windfall’s growth.

When Windfall originally launched, each of our models were individually deployed and managed. If we needed to use a model, oftentimes we’d need to drag in the data scientist who built the model to simply figure out how to properly use it and the required features for prediction. This resulted in potentially multiple hours of inefficient back and forth. In order to combat this, we developed a solution called Model Manager.
With the Model Manager solution up and running, a data scientist can deploy a new or updated model to production within minutes by simply merging the code changes into the master branch of a GitHub repository. The deployment process is entirely standardized, and the model is made accessible to any user through a robust and rigid API. No knowledge of who built the model, how the model was built, or where the model lives is needed. Given our entire model library is exposed by a standardized API, this allows engineers, data scientists, and non-technical users via a UI to easily access and use these models. Today, Model Manager is supporting over 150 models, and we feel it can easily support several orders of magnitudes more.
Determining Model Manager’s Requirements
Before we began down the road of rolling our own application, we compiled a list of must have requirements:
- Standardization. First and foremost, we wanted to standardize the way a user or other application interfaces with existing models. It should be easy to discover and use new models as well.
- Decouple the engineering and the data science. Data scientists should be empowered to independently deploy their own models. Engineers should not be needed for every new model or updated model change.
- Seamless Continuous Integration & Deployment (CI/CD) pipelines for model deployment. Similarly, we wanted to automate the model deployment for the data scientists. A data scientist pushes a change for a model and — poof — the new model version should be deployed. This would also mean adding extensive testing and decoupling the models from each other to ensure one “bad” model doesn’t bring the entire system down.
- Freedom of choice for programming language and libraries (within reason). This applies to both parties involved — data scientists and engineers. In addition to individual preferences, the best choice for building a model will most likely not be the same as building a scalable REST service. While Windfall has many technology standards, we’d like to play to individuals’ strengths here.
- Support for both real-time and batch predictions. Technically, the real-time approach could cover the batch operation, you would just need to do a lot of them. Due to the efficiency and cost benefits, we decided that explicitly supporting batch jobs would be beneficial, given our historical infrastructure was more suited for this approach.
- Autoscaling support (including both upscaling and downscaling). If we kick off multiple prediction jobs, we’d like the system to scale up appropriately and ideally not run serially for performance concerns. On the other hand, if we were to only use a model for a batch prediction once a week, then it shouldn’t use any more resources than it needs to and only when it needs to. We pride ourselves on being a lean organization, and the downscaling capability here is important.
Available Options
There are a number of options available that attempt to solve this problem. And most of them do a very good job at parts of the problem. However, we felt that none of these solutions completely solved our specific use case and checked off all of the items on our requirements list. This isn’t to say we won’t use these options in our solution, but as of now, we are not yet using any of these. We’ve outlined a few of the potential technologies below.
MLFlow, Cortex, SageMaker
These 3 options all assume we want to create only real-time REST services. While they seem to do a fantastic job at this and have plenty of happy customers, we have a hard requirement for support of batch jobs. Additionally, Windfall is on Google Cloud Platform and at the time of this writing, Cortex and SageMaker only support AWS environments. So unfortunately, these are out.
H20
H20 is the closest thing to an almost off-the-shelf solution for our use case. It has multi-language support and allows serialization of trained models across these various languages. Unfortunately, it understandably requires that you pretty much completely buy into the H20 world. At the time we began this project, there was still some functionality lacking that other R libraries or Python packages offered. We decided we’d rather not commit to a single framework and its limitations.
Windfall’s Solution — Built for Scale: Model Manager
Given that we could not find a solution we could purchase and implement, we decided to build our own. Here’s a sneak-peak on how it works:
Model Manager’s sole responsibility is as the name suggests: to manage our models. This means it serves as a registry for any model our data science team creates and any request to use one of these models goes through Model Manager. Model Manager is actually more of a framework, rather than a single application.
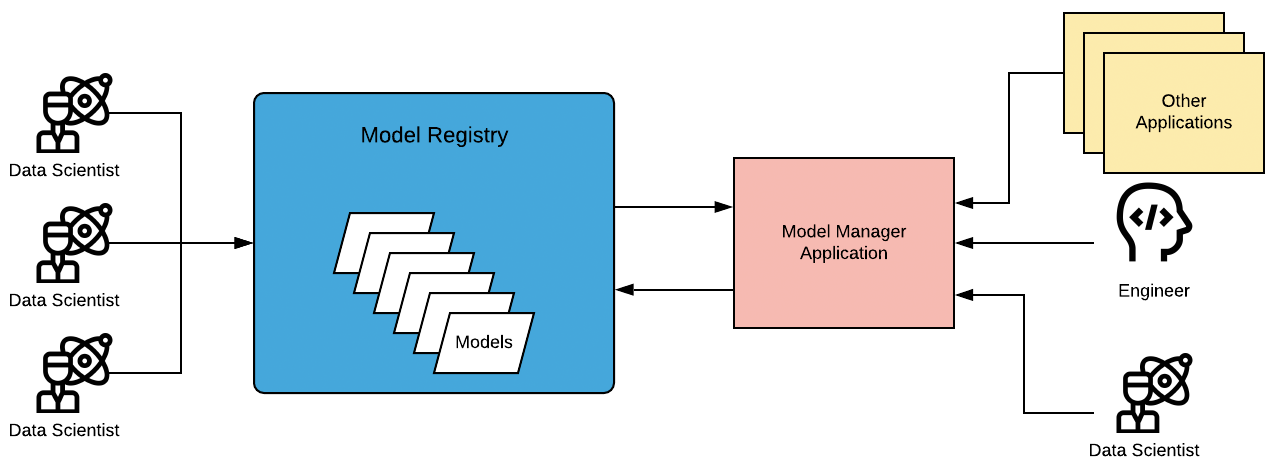
There are two main components to Model Manager: the application layer and the model registry. The application layer is a lightweight, user-friendly API. It simply acts as a request router and delegates the heavy lifting to the models themselves. The model registry serves as a standardized library of all our models, which the application layer can browse as needed. The end user only needs to understand how to interact with the API. Each of the models in the registry is running in a Docker container on Kubernetes. The registry reveals which containers need to be spun up and executed, allowing the model’s container itself to hold the business logic around the model.
Model Registry
We save our models in a completely separate repository that includes a variety of libraries and programming languages. Each model has a few configurations and endpoints that it needs to define in order to successfully register with Model Manager. These configurations include, for example, whether it’s a real-time or batch job and the required features needed for prediction. Depending on if the model is real-time or batch, it may need to configure and/or expose a small set of additional endpoints.
In order to limit the amount of engineering work of the data scientist, our automated CI/CD pipeline is responsible for deploying the models and registering it with the model registry. Once the model exists here, it can be used immediately through the Model Manager application.
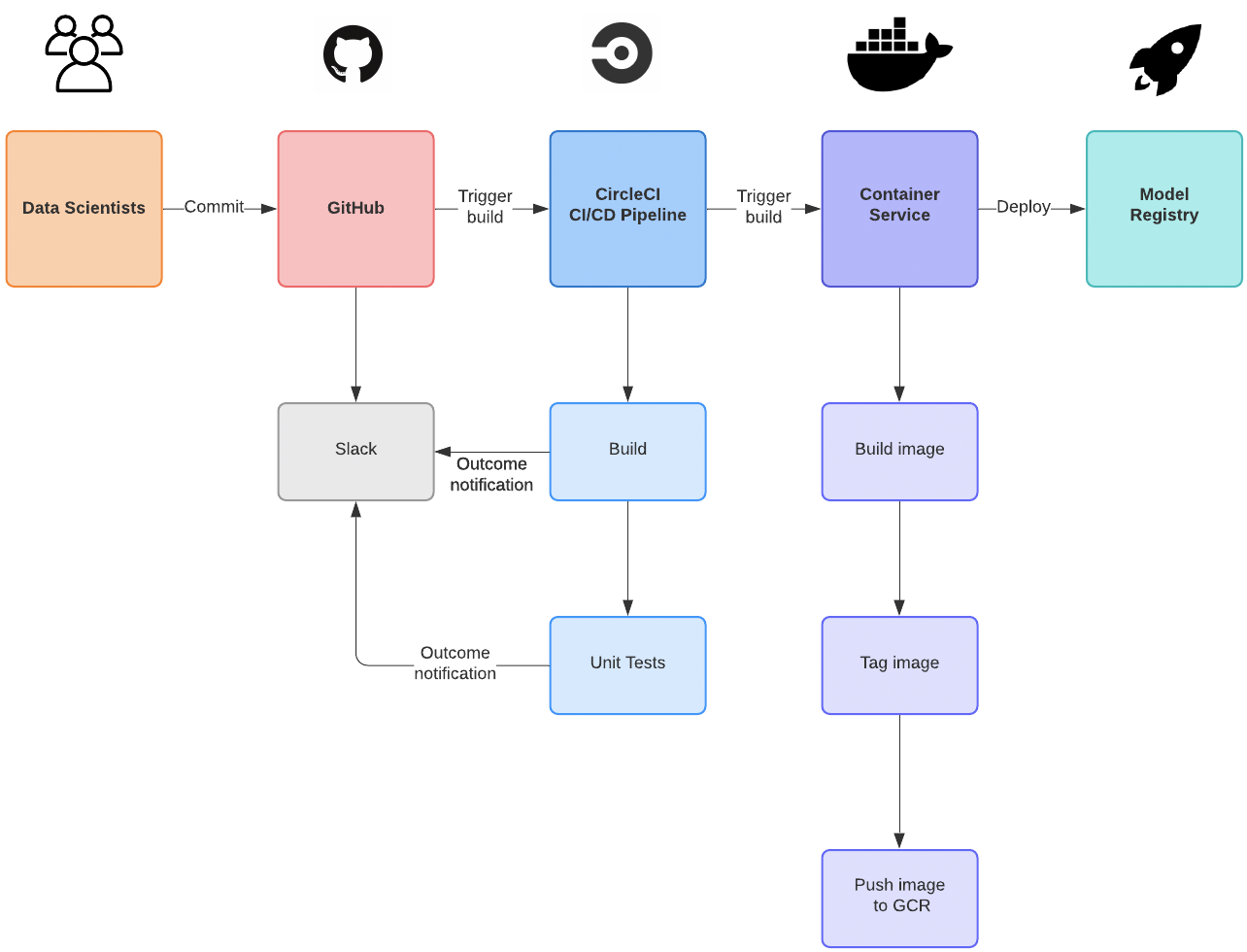
Upon opening a new Pull Request, the CI/CD pipeline runs a rigorous set of tests to ensure that each model is configured properly. Similar to unit and integration testing, this offers a quicker feedback cycle for broken code. This allows a data scientist to be alerted within a minute or two whether or not their model can successfully register with Model Manager instead of waiting for hours, days, or maybe even weeks before it’s used in production.
When merging the change into master, the pipeline will build the Docker image for the model, generate the appropriate configurations necessary for the model registry, and deploy into production. It’s important to point out that we are pushing new configurations and version-tagged Docker images instead of rewriting the existing ones. This allows us to easily compare model changes over time and rollback a model that may not perform as expected.
Model Manager Application
As mentioned earlier, the Model Manager application itself is a very lightweight REST service. It knows how to properly route requests to the appropriate models and interact with the underlying container system, Docker and Kubernetes. Docker allows us to support various programming languages and libraries, and Kubernetes provides us a platform to run these Docker containers. We chose this design because they are well-established technologies. Note that these are completely removed from the data scientist’s responsibility.
Once the models are standardized and containerized in model registry, the tougher part of the problem is solved. Based on the application user’s (engineer, data scientist, or non-technical individual) request, Model Manager finds the appropriate model in our registry and kicks off the container in Kubernetes; batch models are Kuberenetes jobs, while real-time models are always running services.
In addition, the Model Manager application will track the job’s state and ensure that the user receives the successful predictions from the model. This may seem like we need a separate database to back Model Manager, but we actually don’t. The application serves as an API proxy to Kuberenetes, and Kubernetes is the source of metadata for all jobs. This allows the Model Manager application itself to be stateless and removes the database requirement.
Summary
As data and data science is core to our bones, Windfall needed to determine a solution for scaling our data science modeling process. Given that solutions on the market were limited, we wanted to explore building our own proprietary solution that would allow us to satisfy multiple scenarios without feeling significant burden as we grow. To solve our problem, we built Model Manager.
Today, our data scientists can regularly register any new and updated models into Model Manager. They will be automagically picked up and productionized, and our data science team is not burdened with the responsibility or the engineering complexities of managing deployment. Once the models are deployed, users can freely run predictions using any of the models.
We are still working on enhancing the service, but it has already provided us with massive leverage, which only increases with every new model.
Does this seem interesting to you? We’re hiring for our team and would love to hear from you!
To find out more about our services and how we may be able to help your organization, feel free to reach out to our team.
This article was authored by Jeff Kamei, Senior Software Engineer at Windfall. Thanks to Cory Tucker, Patrick Cava, and Arup Banerjee for contributing to this article.



